NavigationUser loginEvents
Who's onlineThere are currently 0 users and 1 guest online.
CategoriesVideoLinks
WikisNoam Chomsky Get Firefox
Mind Hacks
Being Human
Language Log
Brain & Behavior
|
Language LogWhy journalists need to know morphologyAccording to Terry Pedwell, "PMO Iqaluit bumble draws smiles, frowns", The Canadian Press, 8/18/2009: A bumble by the Prime Minister's Office has residents of Nunavut alternately chuckling and cringing. A news release sent out Monday outlined Prime Minister Stephen Harper's itinerary as he began a five-day Arctic tour. The release repeatedly spelled the capital of Nunavut as Iqualuit - rather than Iqaluit, which means "many fish" in the Inuktitut language. The extra "u" makes a big difference. "It means people with unwiped bums," said Sandra Inutiq of the office of the Languages Commissioner of Nunavut.
[Hat tip: Peter Breslauer] [Update — morphological and lexicographic details here.] A little more on Stephen HawkingSarah Lyall's piece "An Expat Goes for a Checkup" (front page of the NYT Week in Review, August 16) disusses American attacks on Britain's National Health Service (and affronted British responses, and her own experiences with the NHS), leading with the Investor's Business Daily invoking the physicist Stephen Hawking in an August 3 editorial opposing Barack Obama's health care proposals. As Geoff Pullum posted here last week, IBD (an American enterprise) barreled into the matter with the (utterly mistaken) assumption that Hawking is an American. The question Geoff asked was where IBD got this idea.
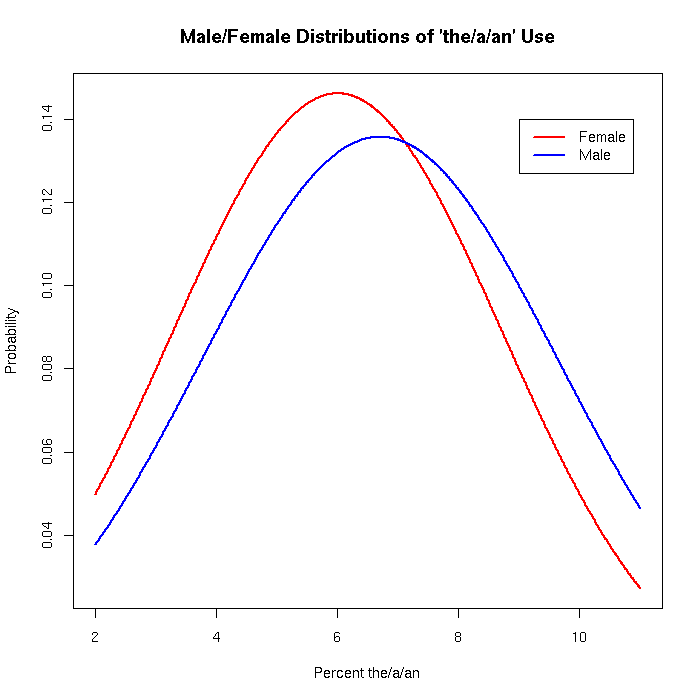
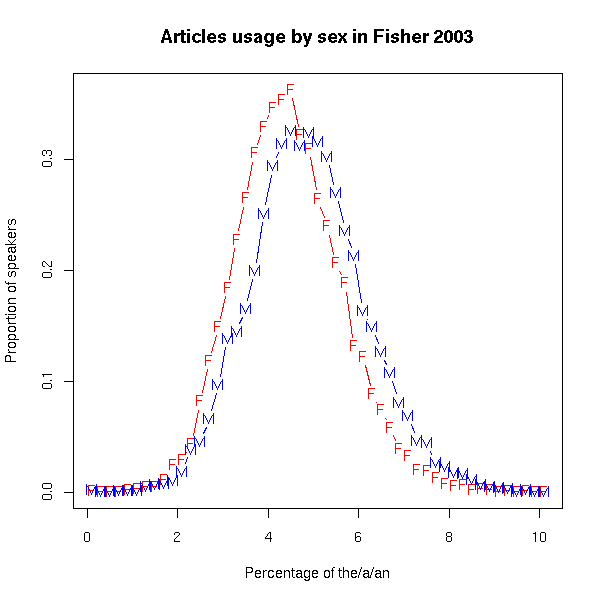
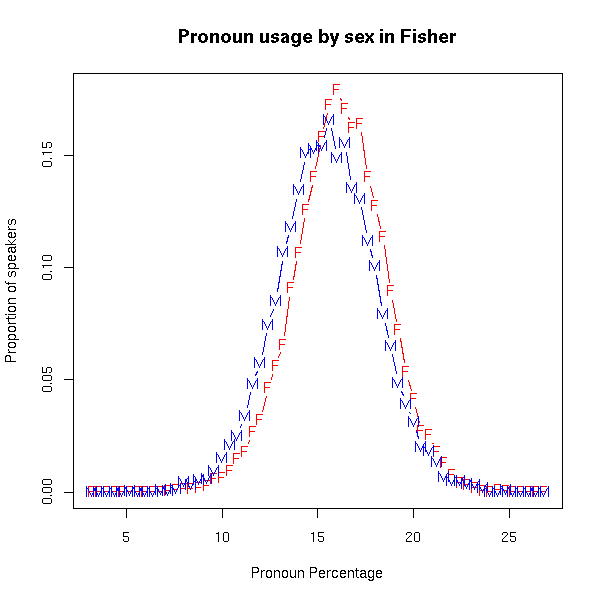
I suggested to Geoff that the (U.S.) Presidential Medals of Freedom might have contributed to IBD's misapprehension, via the assumption that such awards go only to Americans. But this is a misapprehension as well; this year's 16 recipients included not only Hawking, but also Archbishop Desmond Tutu, Mary Robinson (former president of Ireland), and Bangladeshi economist Muhammad Yunus. Unfortunately for my idea, the timing is bad: the award ceremony was on August 12, more than a week after IBD's editorial. So it looks like it's back to the speech synthesizer proposal. [Addendum: Melissa K. Fox writes to say, "while I think Dr Pullum's speech-synthesizer explanation for IBD's confusion has a lot in it, I think there might be something in the Medal of Freedom explanation as well — the ceremony was August 12, sure, but the recipients were announced July 30, several days before the editorial. You can both be right!"] Think B4 You SpeakAccording to Tycho at Penny Arcade ("The True Face of Our Enemy", 8/17/2009) The Think B4 You Speak campaign is basically incoherent, and operates from some deep misconceptions about how and why people communicate. These assertions have been collated and placed sequentially in today's comic offering The strip in question: (Click on the image for a larger version.) His conclusion: No-one responds to this kind of diffuse scolding, least of all young men, least of all from strangers who present themselves as archwizards of prim speech and perfect morality. Bigots and stupid kids speak this way expressly to promulgate the root concepts or to provoke a reaction. Telling them to "knock it off," as this campaign hilariously does, is like exposing your belly to these wolves. Lexically speaking, the word Gay is a battleground of warring meanings, uses, and baggage. The fact that the slur has retained its power - for all parties involved - is evidence that the conflict is ongoing, and that its destiny is not yet established. I have tremendous support for them in their aim: the wresting of language, which is identity, from the unworthy foe. If you want to hunt this kind of game, you need bigger ordnance. This is only partly true, it seems to me. First, a lot of people do respond to such campaigns. In some cases, they respond by complaining about "political correctness", or in other negative ways; but often, they actually try to modify their language, as complicated and confusing as that sometimes seems to be. It's true that the people who change their usage are generally not the people with genuinely offensive attitudes — but the campaign is specifically aimed at those who offend others without really wanting to do so, not at hard-core bigots. And second, people's word choices are sometimes ignorant rather than thoughtless. I was in my 20s before I learned that gyp (meaning "cheat") had anything to do with gypsies. It's not that I thought it didn't — I just had never given the question any thought at all, because it had never occurred to me to do so. A friend of mine often used the expression "jew down" (as in "I jewed the dealer down to 5% over his cost"); when I pointed out to him that this reinforced anti-semitic stereotypes in an especially ironic way, since he as a WASP was a notoriously tenacious bargainer, he was taken aback, and claimed never to have realized that there was a connection between "jew down" and jews. And I once met a college freshman who was convinced that gay as a term for sexual orientation was derived from a pre-existing word meaning "foolish, stupid, socially inappropriate or disapproved of", rather than from a pre-existing word meaning "brilliant, showy, merry, sportive". It's true that campaigns of this kind are generally pretty ineffective. "Just say no" and "This is your brain on drugs" seem to have enriched the culture's stock of catch-phrases without having much impact on the popularity of sex and drugs. But maybe political correctness is different. No non-Portuguese textbooks?I was just looking for something in international mail regulations and stumbled on something curious. Among the items that it is prohibited to send to Brazil are: "Primary educational books not written in Portuguese". I have no desire to send any such textbooks to Brazil - in fact I'm not planning on sending anything to Brazil - I noticed this while looking for something else - but I'm curious as to the reason for this prohibition. It stands to reason that in a country whose primary language is Portuguese most primary textbooks will be in Portuguese, but I should think that there would be some schools in which some textbooks are not, such as international schools. And even if no schools use such textbooks, I can imagine foreign residents importing books in their own language for the use of their children, or teachers and educationists who want to examine textbooks from other countries. Against these legimitate uses for non-Portuguese textbooks, it is hard to imagine the threat posed by non-Portuguese textbooks. Do any of our readers know what this is about? My illiterate search for the Sicilian animals (3)Well, now it is time to tell you the answer. (If you are saying "The answer to what?", you're in the wrong place. Start here, then go to here, and then come back.) Before I do, I should mention that half the readers of Language Log seem to have mailed me with their suggestions or quibbles or whatever. I'd like to express my sincere thanks to the other half. For the ones who suggested "sessilians", sorry, there are indeed animals that are sessile (rooted to the spot and immobile), and even a kind of barnacle called the sessilia, but they do not constitute an order called "sessilians" — you made that word up. But I never did find the word via dictionaries or word lists. (By the way, I fixed up the original post to mention that people had pointed out that the initial letters could have been ps- for all I knew. Quite right. But that turned out to be just another red herring to follow.) The way I found the order in question was through aimless searching of zoological taxonomies. I had a vital clue that you didn't have: I had heard Sir David refer to the Sicilian creatures in the same breath as amphibians and snakes. So I just went to Wikipedia and just started working up from reptiles and amphibians to older and more inclusive classes, going back and forth and following links to possibly relevant articles about reptilia and amphibia, until by accident I hit upon one that had a link to the order I was looking for (but had never heard of before): the caecilians (their order is also known as the Gymnophiona or a Apoda). Strange animals indeed. Blind subterranean legless amphibians with teeth, living only in the tropics. Very little is known about them in some respects. Fascinating. I really want to see one now. And my temporary illiteracy is over, thank goodness. The people who figured it out were largely people who had heard the Radio 4 program and were thus equipped with the clue that they should look up amphibians and browse around in that biological area. As far as I know, virtually no one got it by searching dictionaries or word lists. The spelling defeated us all. Except for Bill Walderman, who hit on the brilliant and very rapid technique of telling Google to search for "cycilian": it promptly corrected him to "caecilian" and showed him pictures! Nice work, Bill. Honorable mention. But The very first person to mail in a correct answer was Paul Bickart — exactly thirty minutes ahead of the second, Ast Moore. All three of these will have their subscription fee to Language Log waived for one year as a prize. The etymology of caecilian, by the way, goes back to a Latin root for blindness, or (equivalently) the Latin word for the "slow worm", which is a legless lizard that lives under things (it is not actually blind, but the Romans apparently thought it was). Computational eggcornologyChris Waigl, keeper of the Eggcorn Database, brings to our attention a paper that was presented at CALC-09 (Workshop on Computational Approaches to Linguistic Creativity, held in conjunction with NAACL HLT in Boulder, Colorado, on June 4, 2009). As part of a session on "Metaphors and Eggcorns," Sravana Reddy (University of Chicago Dept. of Computer Science) delivered a paper entitled "Understanding Eggcorns." Here's the abstract: An eggcorn is a type of linguistic error where a word is substituted with one that is semantically plausible – that is, the substitution is a semantic reanalysis of what may be a rare, archaic, or otherwise opaque term. We build a system that, given the original word and its eggcorn form, finds a semantic path between the two. Based on these paths, we derive a typology that reflects the different classes of semantic reinterpretation underlying eggcorns. You can read the PDF of Reddy's paper here. Yet another advance in the recognition of eggcornology as a legitimate linguistic subdiscipline. My illiterate search for the Sicilian animals (2)You shouldn't be reading this if you didn't read My illiterate search for the Sicilian animals (1): if you're starting here, don't. Follow this link and read that first. Then come back. Because all I am doing in this brief follow-up post is giving Language Log readers a clue concerning the crucial feature of the awful English spelling system that I had temporarily forgotten. I had forgotten (how?) about the emperors of Rome, and the most southeasterly of that city's hills, and bypassing the birth canal, and the radioactive soft metal isotope used in atomic clocks, and the opening part of the large intestine. That's your clue. (What do you mean that's not enough? I'm the quizmaster here. I'm the one who says what's enough.) A word on the wall"Best. Cartoon. Ever", says Jesse Sheidlower, about The Rut for 7/15/2008: "Well, maybe not greatest, but I really love this", he hedged. The and a sex: a replicationOn the basis of recent research in social psychology, I calculate that there is a 53% probability that Geoff Pullum is male. That estimate is based the percentage of the and a/an in a recent Language Log post, "Stupid canine lexical acquisition claims", 8/12/2009. But we shouldn't get too excited about our success in correctly sexing Geoff: the same process, applied to Sarah Palin's recent "Death Panel" facebook post ("Statement on the Current Health Care Debate", 8/7/2009), estimates her probability of being male at 56%. Although it's easy to make jokes about this, it's based on a solid and interesting result. A recent survey (Newman, M.L., Groom, C.J., Handelman, L.D., & Pennebaker, J.W., "Gender differences in language use: An analysis of 14,000 text samples", Discourse Processes, 45:211-236, 2008) looked at more than 50 "linguistic dimensions", and the difference in use of the/a/an was one of the largest sex differences found. A few days ago, in a post on "Linguistic analysis in social science", I observed that Traditional mass media are now nearly all digital; new media are documenting (and creating) social interactions at extraordinary scale and depth; more and more historical records are available in digital form. The digital shadow-universe is a more and more complete proxy for the real one. And in the areas that matter to the social sciences, much of the content of this digital universe exists in the form of digital text and speech. As a result, I argued, data based on the analysis of speech and language will play an increasingly large role in the social sciences. The relevant effects are generally small ones, but they're easy to measure, and when properly characterized and measured, they can be quite reliable. Furthermore, they're similar in magnitude to effects measured with much greater trouble and expense using traditional social-science methods like surveys and tests. So for today's lunch experiment™ (I was busy with other things over breakfast…) I thought I'd see if I could replicate Newman et al.'s result on sex differences in article usage, using a completely different data set. First, let's get clear on what Newman et al. found. Their abstract: Differences in the ways that men and women use language have long been of interest in the study of discourse. Despite extensive theorizing, actual empirical investigations have yet to converge on a coherent picture of gender differences in language. A significant reason is the lack of agreement over the best way to analyze language. In this research, gender differences in language use were examined using standardized categories to analyze a database of over 14,000 text files from 70 separate studies. Women used more words related to psychological and social processes. Men referred more to object properties and impersonal topics. The summary table of dimensions and effect sizes is on pages 19-20, reproduced for your convenience here. The results for percentages of the/a/an, in particular, were: Female mean (stddev) Male mean (stddev) Effect Size 6.00 (2.73) 6.70 (2.94) d = -.24The "effect size" here is estimated using "Cohen's d", which is the difference in means divided by the pooled standard deviation. This difference in article-use percentage is on the large side, not only among sexual-textual characteristics, but also among cognitive sex differences in general, for example the measures of verbal ability in meta-analytic studies like Janet Shibley Hyde and Marcia C. Linn, "Gender Differences in Verbal Ability: A Meta-Analysis", Psychological Bulletin, 104:1 53-69 (1988). For more on the interpretation of effect sizes in general, see "Gabby guys: the effect size", 9/23/2006. In this case, if we assume that the distribution of article-use percentages by sex is "normal", then over a large collection of writing-samples, the cited means and standard deviations would yield a distribution of percentages like this: It's important to be clear that this is not a very big effect, when you look at it from the point of view of men and women as individuals. Since the correlation ("Pearson's r") is related to Cohen's d as r = d/sqrt(d^2 + 1/(p*q)) (where p and q are the proportions of the two groups being compared), and since their sample was about 58% female, the correlation between sex and article use should be about r = 0.119 — and thus the percent of variance in article use that is accounted for by sex, in their dataset, is about r^2 = 1.4%. Looking at it from the other side, you'd have around a 55% chance of guessing sex from the percentage of the/a/an in random examples drawn from a population with equal numbers of males and females exhibiting these distributions of article-usage by sex. And there are bigger differences due to genre and topic — the rate of the/a/an usage in formal written text will generally be much higher than in informal conversation, for example, and the expected magnitude of that difference is more than twice as great as the sex effect. So this sex difference in article usage (like other perceptual and cognitive sex differences) doesn't provide any meaningful scientific support (in my opinion) for Dr. Leonard Sax's single-sex-education movement. On the other hand, differences of this magnitude can be quite important in some contexts. This much of an edge in investing or gambling, for example, would be a reliable source of income. Similarly, in politics or in marketing, effects of this size can be highly useful. (I don't mean that article-usage distributions per se are of any interest to investers, politicos, or marketeers; but other reliable effects of this size certainly would be.) And a correlation of about 0.12 is right in the mix, for effects in published social-science research. Compared to the values in a recent meta-analysis (F.D. Richard, C.F. Bond, and J.J. Stokes-Zoota, "One hundred years of social psychology quantitatively described", Review of General Psychology, 2003), it's below the mean, but above the mode: This article compiles results from a century of social psychological research, more than 25,000 studies of 8 million people. A large number of social psychological conclusions are listed alongside meta-analytic information about the magnitude and variability of the corresponding effects. References to 322 meta-analyses of social psychological phenomena are presented, as well as statistical effect-size summaries. The distribution of r values that they found: OK, on to the replication. In order to show that this effect is reliable and easy to calculate, I took the transcripts and speaker demographics from the Fisher Corpus of conversational speech, a collection of more than 10,000 telephone conversations lasting up to 10 minutes each, recorded in 2003-2004 and published by the LDC. In 9,789 conversational sides spoken by males, I found 9,409,848 words, of which 471,820 were the/a/an, for an overall percentage of 5.01%. In 13,007 conversational sides produced by females, there were 12,186,985 words spoken, including 554,827 articles, for an overall percentage of 4.55%. These percentages are lower than in Newman et al.'s overall tabulation, as we expect given that this is informal conversation rather than written text. What about the distribution of percentages across speakers? Here's a graphical representation of what I found (0.2%-wide bins from 0.1% to 10.1%): And here's a table of the summary statistics Female mean (stddev) Male mean (stddev) Effect Size 4.47 (1.16) 4.89 (1.27) d = -.34Thus the effect is in the same direction, and the effect size is somewhat larger, consistent with Newman et al.'s observation that Although these effects were largely consistent across different contexts, the pattern of variation suggests that gender differences are larger on tasks that place fewer constraints on language use. The key thing is that this kind of analysis is now very easy to do. Starting from the raw Fisher-corpus transcripts and metadata files, writing and running the (gawk and R) scripts for this replication took me 17 minutes of wall clock time. I haven't tried to persuade you that this effect is an interesting one, only that it's reliable (in the aggregate), comparable in size to many traditional social-psychological measures, and easy to compute. Though something might be learned by trying to figure out where this phenomenon comes from, it seems to me that it shouldn't be seen as an end in itself, but rather a feature that might help us understand other social and psychological differences. There are hundreds of features that can now be calculated in similarly trivial ways. (And the resulting distributions show large age, class, and mood effects as well as sex effects, as Jamie Pennebaker and others have found — are there also effects of political philosophy, for example?) As more and more text and speech become available, as better and more sophicated automatic analyzers are developed (such as those involved in "sentiment analysis"), and as the modeling of feature distributions in these larger datasets becomes more sophisticated, it's inevitable that the scope of such research will become broader, and the number of studies will increase. I believe that the social value and intellectual interest of these studies will also increase — and I'll try to persuade you, in occasional future posts, that this is already happening. [Update: D.O. in the comments asked about pronoun percentages. The numbers from Newman et al. are Female mean (stddev) Male mean (stddev) Effect Size 14.24% (4.06) 12.69% (4.63) d = 0.36I'm not sure that I've replicated their calculations exactly, because I'm not certain my list of pro-forms is the same as theirs. But for what it's worth, here's what I get for the Fisher data: Female mean (stddev) Male mean (stddev) Effect Size 16.155% (2.352) 15.496% (2.531) d = 0.27And here's the graphical version: Again, the direction is the same, though there's an effect of genre that's larger than the effect of sex.] My illiterate search for the Sicilian animals (1)My parents tell me that I could read well before my 4th birthday. As a result, I have virtually no experience of what it would be like to be illiterate. It would be easier for me to imagine blindness than complete inability to read. I did have a glimpse of it when I first spent some time in Japan, and was surrounded by an advanced culture using an utterly alien writing system in which I couldn't even read out the names off the signs (as I can in any of the alphabets of Europe). But I had another glimpse this morning when I heard a word on the radio that I couldn't guess how to spell, not even vaguely. Tracking it down was a terrible job. My dictionary was no help, precisely because dictionaries are organized in such a way as to be helpful only to the literate. The great naturalist Sir David Attenborough, on Radio 4, mentioned a curious-sounding class of animals that he appeared to be calling Sicilians. (Not a class in the technical terminology; technically they are actually a whole separate order of animals.) I listened carefully; it definitely sounded like "Sicilians". But what was this word? These creatures (he made it clear) did not live in Sicily. The only letters that can represent the [s] sound are c and s. (Just in case, I checked x and z, which actually represent [z] when initial; I thought perhaps I had misheard the voicing. But I had not; it was a blind alley, and I will ignore it hereafter. People have pointed out to me since I wrote this that the silent p words like psychology reveal another possibility. True. But it turned out not to be relevant.) The vowel letters that could represent [I] after [s] would be i as in city or sit and y as in cyst or system, and just possibly (in an unstressed syllable) e as in Cecilia or serenity. It couldn't be a or o or u, because before those letters a c stands for the stop consonant [k]. And the third sound, the second [s], could be spelled (for all I knew) c or s or ss. And I came up with zip. Nada. Nichts. Nothing. There I was, illiterate in English (while holding the position of head of the top Linguistics and English Language department in the U.K. — what a fraud!), fumbling through the dictionary, unable to find a word — solely because dictionaries are organized entirely on the assumption that you know how to spell, at least to an approximation. I found no sign of the word at all, in any of the relevant places. I simply couldn't remember this happening to me before. Most unpleasant. So this is how adult illiteracy feels. Dictionaries become useless. Now, I do have a fair command of Unix tools, and those, used appropriately, can dramatically reduce your feelings of illiteracy and inadequacy. I knew that what I had to find was in the set of all words that would match the egrep regular expression: "^[cs][iey](c|ss?)". That is, I wanted to see a list of any words beginning with c or s followed by i or e or y followed by either c or else s with perhaps a second s after that. (To allow for ps-, the expression could be modified to "^(ps|[cs])[iey](c|ss?)". Doesn't make any difference.) On any Unix system you can use the egrep program to produce an exhaustive list of all of them by searching the standard word list in /usr/share/dict/words (it is /usr/dict/words on some systems). In fact you can make egrep give you a list of all the words that begin the right way and include an l (there had to be one of those in the word) and ends in n plus (just possibly) a silent e. So I tried the magic of egrep. I typed this to the prompt in the Terminal program on my Mac OS X laptop: egrep "^[cs][iey](c|ss?)[a-z]*l[a-z]*ne?$" /usr/dict/share/words But the results were disappointing: the four words it comes up with are cyclone, cyclopean, cyclotron, and seclusion. No plausible candidates there. Where the hell was this zoological word that sounded just like Sicilian that I had never heard before and that couldn't be found in an excellent dictionary or in the Unix standard word list? I turned to a larger word list. There is a 235,000-word list in a file called /usr/dict/web2 that is now supplied with many Unix and Linux systems (it is linked to /usr/dict/share/words on some of those), and I tried out this command: egrep "^[cs][iey](c|ss?)[a-z]*l[a-z]*ne?$" /usr/dict/web2 And I still drew a blank. I found out later that the word is in there, but the above command will not find it. It produces this list of 45 words (which reveals to you why web2 is often less useful than the shorter list — it is way too big, and contains all sorts of learned and scientific junk): ciclatoun cyclene cyclohexanone cyclopentadiene seclusion cisalpine cyclian cyclohexene cyclopentane sectionalization cisleithan cyclization cycloidean cyclopentanone secularization cisplatine cycloalkane cycloidian cyclopentene sesquialteran cycadofilicinean cyclobutane cyclomyarian cyclopropane sesquipedalian cyclamen cyclodiolefin cyclone cyclothurine sicilian cyclamin cycloheptane cycloolefin cyclotron sicilienne cyclamine cycloheptanone cycloparaffin secalin sickleman cyclane cyclohexane cyclopean secaline sysselmanWell, it turned out that I was missing something. Eventually I did track the word down, by a less orthodox technique, not based on the alphabet. And then I knew the crucial orthographic fact about English that I had been overlooking. It didn't seem so arcane once I reached that point. But until then it was completely opaque to me. Let me explain… No; on second thoughts, I don't have a lot more time right now, and it will be fun for you trying to figure it out. I will tell you tomorrow, and I'll explain how I tracked down the word. [Comments cannot be allowed at this point, of course, because Language Log now has tens of thousands of readers and many of you are extremely smart, and others are zoologists (in addition to being extremely smart), and you would blow the puzzle within three minutes flat and tell everyone what the secret was.] The 2009 Linguistic Institute endsYesterday the six-week faculty and the second-session three-week faculty ended our teaching stints at the 2009 Linguistic Institute sponsored by the Linguistic Society of America and the University of California at Berkeley. The two second-session Language Loggers, Adam Albright and I, were in complementary distribution with the two first-session Language Loggers, Geoffs Nunberg and Pullum: we did not meet in Berkeley. Not all of us have finished our work for our classes — I still have 15 of my 42 papers to grade — but our tight-knit community — living in the same dorm, sorry, residential unit (palatial by my loooong-ago student-era standards) and eating at the same university dining hall (spectacular by my ditto standards) — is history. What a great Institute! I learned any number of cool things, partly from my own students (who hailed from places as distant as Florida, Boston, Singapore, France, Poland, and Taiwan), partly from the two classes I sat in on, Adam Albright's morphological change class and Emmon Bach & Pat Shaw's class on Wakashan Linguistics, and partly from fellow faculty members. From my students I learned, for instance, about Singapore's Speak Good English Movement (launched in 2000 and based on the earlier Speak Mandarin Campaign, vintage 1979, which was designed to encourage Chinese speakers to abandon other Chinese "dialects" and switch to Mandarin). The SGEM is supposed to promote Standard Singapore English and demote "Singlish", a.k.a. Singapore Colloquial English. I also learned about Bhindi, a mixture of Hindi and Marathi and maybe Dravidian languages as well, spoken in Bombay/Mumbai. And the students raised the question of whether the Nicaraguan Sign Language is best seen as a pidgin, or a creole, or something else. (I argued for abrupt creole status, on the grounds that the Deaf kids who created it brought their home-sign systems to the school where the NSL developed, and presumably contributed material from those sign systems to the emerging creole.) From Mark Donohue, who was teaching Phonological Typology of Papuan Languages in the second session, I learned a whole bunch of fascinating things: about the Doutai speakers (NW New Guinea) who suppressed their language's implosive consonants for several weeks while Mark was studying their language (a phenomenon reminiscent of Dan Everett's experience of living three years among the Pirahas in the Amazon before they stopped suppressing their linguo-labial stops in talking to him); about plugging in typological features — word order, consonant types, etc., etc., etc. — to biologists' statistical models and coming up with areal rather than genetic groupings in known cases (e.g., Rumanian grouped with Slavic rather than with the rest of the Romance languages); and about a wide range of other things. There's lots more, but you'll have to attend an LSA Linguistic Institute yourself — say, in Boulder, Colorado, in 2011 — to get your own collection of exciting linguistic facts, perspectives, new theories. No matter how old or young you are in age and/or in the field of linguistics, there's something at an Institute for you. About half the students in my language contact class at this Institute were undergraduates, for instance, and a few of them were studying at almost linguistics-free colleges. Neophytes, in other words. And they did just fine. For language-lovers, it doesn't get much better than a Linguistic Institute. And that's even aside from the occasional perks, like the view of the Golden Gate Bridge from my dorm window. When peeves collide… the result is a grammatical bar brawl. An excellent example is on display over at Ask MetaFilter, where someone innocently asked So which sentence is proper English grammar: "If you eat like Bob and me, you will be healthy." or "If you eat like Bob and I, you will be healthy." KA-POW: "it's the second one…" WHAAM: "No, it's the first…" BIFF: "The verb 'do' is implied…" DOINK: "'like' … is indisputably a preposition in this case. It can't even function as a conjunction." And so on. There's some sensible and well-informed advice mixed in with the mud and the blood and the beer, including a link to my discussion of a similar question a few weeks ago ("Write like me?", 7/24/2009). But overall, the chaos of contradictory confidence is likely to reinforce the culture's general state of nervous cluelessness about grammar. In this case, an ample supply of the relevant clues can be found in two entries in MWDEU. The first is the entry for between you and I (p. 181-182): And the second is the entry like, as, as if (p. 600-603): Unfortunately, the answer suggested by the MetaFilter free-for-all still stands — no matter what you do with this question, some peevologist is likely to take a poke at you. But maybe this background will help you get out of the place in one piece. ComparedSome interesting posts recently by Brett at English, Jack: "A newly discovered preposition", 8/7/2009; "More evidence for 'compared' as a preposition", 8/11/2009: I believe that I may be the first person to have realized that compared is a preposition. It is not listed as such in any of the dictionaries that I consulted, and you may very well be wondering how compared could possibly be a preposition. Let me try to explain. Brett's argument starts with the observation that sentence-initial participial adjuncts are often felt to be "danglers" when not predicated of the subject of the following clause. Fearing a massive lay-off, there was a general sense of relief when the boss announced there would be no new budget cuts. In contrast, prepositional-phrase adjuncts don't have this problem: After a massive lay-off, there was a general sense of anger. He then observes that what seem to be past-particle adjuncts with "compared to" behave in this respect more like PPs: Compared to ICS alone, there was a significantly greater improvement in FEV1 with the addition of LABA. This is a valid argument, but not a new one. CGEL discusses it in chapter 7, section 2.3 (pp. 610-611); For the most part, verbs are clearly distinguishable from prepositions by their ability to occur as head of a main clause and to inflect for tense. There are, however, a number of prepositions that have arisen through the conversion of secondary, non-tensed, forms of verbs: [21] i [Barring accidents,] they should be back today. The basis for analysing the underlined words here as prepositions is that there is no understood subject. This is effectively the same criterion as we have used in distinguishing prepositions from adjectives: prepositions can be used in adjunct function without a predicand, i.e. and element of which they are understood to be predicated. The preposition counting in [ii], for example, is to be distinguished from the gerund-participial verb-form in: [22] [Counting his money before going to bed last night,] Max discovered that two $100 notes were missing. The boundary between the prepositional construction [21] and the verbal [22] is slightly blurred by the usage illustrated in: [23] i [Turning now to sales,] there are very optimistic signs. These differ from [22] in that no subject for the underlined verb is recoverable from the matrix clause. They are similar to what prescriptivists call the 'dangling participle' construction illustrated in examples such as *Walking down the street, his hat fell off, ungrammatical in the sense where it was he, not his hat, that was walking down the street. Unlike the latter, however, the examples in [23] are generally regarded as acceptable. They differ from the prepositional construction in that there is still an understood subject roughly recoverable from the context as the speaker or the speaker and addressees together. In his second post on the subject, Brett adds some other examples, as well as a persuasive new argument: Another piece of evidence comes from coordination. Typically parallelism dictates that we coordinate only like with like. It would not typically allow us to coordinate a PP with a VP. In the following sentences, however, we have a PP coordinated with a phrase headed by 'compared':
At least, this shows that the "compared to" phrases are serving as adverbial adjuncts in parallel to the <i>by</i>-PP. A participial phrase that is clearly in apposition with a subject doesn't generally conjoin with adverbials this way: *Unexpectedly and counting her money, Sally found $100 missing. (Those of you interested in the phenomenon of "dangling modifiers" may wish to join the Fellowship of the Predicative Adjunct, though you should be aware of the Fellowship's credo that this is a matter of etiquette rather than grammar.) Roll over Joyce Cary… and tell Lady Gregory the news. According to David Adams, writing in the Irish Times, "Attacks on the language are rising, basically": IT’S OFTEN the little things in life that can get to you. Take “basically”, for instance. I cannot be alone in having grown to detest the very sound of this word. It has become so annoyingly pervasive in the spoken language, you sometimes wonder if we are now incapable of relaying even the most mundane information without employing it. As in, “Basically, I was walking down the road”, or, “Basically, he was standing there”. Only good manners and not wanting to be thought a complete lunatic stop some of us from screaming: “There is no ‘basically’ about it. Either you were walking down the road or you weren’t, or he was standing there or he wasn’t.” While maintaining this tenuous hold on his sanity, Mr. Adams is also seething because in the "blogosphere" (a word he carefully places in scare quotes), "words are regularly invented, mangled or forced against their will from nouns into verbs, or vice versa". It's a lucky thing for his peace of mind that he wasn't around in the 16th century. His penultimate peeve is prosodic (and is thus, by general rule, graced by a missing comma): Continuing on the theme of annoyances is it only my imagination, or is the high rising terminal (HRT) habit that some of us picked up from watching too many episodes of Neighbours and Home and Away on the wane? HRT, as you probably know only too well, is where sentences end with an upward intonation, so that every utterance sounds like a question posed by an Australian. Since the origin of this pattern is apparently in a geographical cluster of English varieties that includes part of Ireland (see here and here), it's interesting to see Mr. Adams identifying it as an import from Australia. Perhaps this means that the Australian version really is phonetically different — though I haven't been able to find any way to measure it that shows this to be true — or perhaps this is like the Pennsylvania student once interviewed on television about uptalk, who said something like "Well, my friends and I don't talk that way? I think that's something that the kids in New Jersey do? But I don't think you'll hear it around here?" Adams continues: I certainly hope it is on the way out. I suspect, though, I’ve only stopped noticing through being distracted by another antipodean import that appears to be gaining ground. I speak of that increasingly common opening to a usually uninvited declaration by mostly self-obsessed people of what they intend doing or saying next: “Do you know what . . . ” This is the most puzzling of Adams' peeves. He's complaining about Ireland recently importing from Australia something that's been a standard rhetorical device since the time of Plautus. Thus Henry Baker's 1739 translation of Molière's The blunderer: Trufalin: Hark'e, dost thou know what I have just been doing? Language must indeed be a sad state among the Irish, if they need to send to Australia and New Zealand for this ancient device. Update — several people have suggested that I add the latest Partially Clips comic to this post:It swaps the histrionics from one side to the other, but still… I thought I'd also observe that (as a matter of mere fact) use of basically isn't even close to the point where "we are now incapable of relaying even the most mundane information without employing it". Specifically, according to blogpulse.com, the proportion of blog posts containing it is well under 1% (about 0.65%, more exactly): And as usual, the discussion in MWDEU is a sensible one: As a ruleYesterday Rob S wrote to ask about a sentence from the newspaper ("Women's Work and Japan's Hostess Culture", NYT, 8/11/2009): "A recent New York Times article described the Japanese profession of hostessing, which involves entertaining men at establishments where customers pay a lot to flirt and drink with young women (services that do not, as a rule, involve prostitution)." So, does this quote mean that there exists a rule that says it cannot involve prostitution? Or is it rather stating that there is no rule that it must involve prostitution? Is it forbidden, or just not required? I responded, somewhat unsympathetically, with the opinion that "as a rule" is just a quantifier over instances, meaning something like "in general" or "in most cases", and not evoking any concept of a rule in the deontic sense at all. This invalidated Rob's curiosity about "whether there was the absence of some rule mandating it, or the presence of a rule forbidding it". Rob was a bit disappointed, I think, so I decided to try to do better, first by confirming my impression of how the expression "as a rule" is now used, and second by tracing its history to see if his interpretation has a basis in the past. In contemporary examples, no mandating or forbidding is (as a rule) anywhere in sight. From the current harvest at Google News: As a rule, observational studies like this are less reliable than placebo controlled trials. These quotations don't imply any sort of regulation or mandate. They're all just ways of talking about how things generally are, not how they should be or must be. And it seems that the foundation for this non-regulatory interpretation goes back to middle English. The OED's entry for rule, n. has a sub-entry for sense 11.a. glossed as "A fact (or the statement of one) which holds generally good; that which is normally the case". The citations for this sense go back to 1300. This sense is extended in 11.b. to the expression as a (or the) rule, glossed as "normally, generally". However, the citations for this expression only date from 1842 — and without context, it's hard to be confident that the first two of them don't carry at least a tinge of the "regulation" sort of meaning: 1842 CHRISTIE in Fleury's Eccl. Hist. I. 137 note, The Oblation was, as the rule, made in the morning. So I turned to Literature Online to see whether the regulatory nature of "as a rule" might have changed over time. And I found that it seems to have done so. Before 1800 or so, the examples are almost all part of expressions like "laid down as a rule", "established as a rule", etc., which have a distinctly regulatory flavor. A typical (if ironic) example can be found in the opening passage of Henry Fielding's 1749 novel Tom Jones ("Of the SERIOUS in writing; and for what Purpose it is introduced"): Peradventure there may be no Parts in this prodigious Work which will give the Reader less Pleasure in the perusing, than those which have given the Author the greatest Pains in composing. Among these probably may be reckoned those initial Essays which we have prefixed to the historical Matter contained in every Book; and which we have determined to be essentially necessary to this kind of Writing, of which we have set ourselves at the Head. For this our Determination we do not hold ourselves strictly bound to assign any Reason; it being abundantly sufficient that we have laid it down as a Rule necessary to be observed in all Prosai-comi-epic Writing. Or in a more sober vein, Sir Joshua Reynolds' 1778 address to the Royal Academy: It would be useful to a Painter to enquire into the true meaning and cause of rules, and how they operate on those faculties to which they are addressed; by knowing their general purpose and meaning, he will often find that he need not confine himself to the literal sense, it will be sufficient if he preserves the spirit of the Law. It is given as a rule, for instance, by Fresnoy, That the principal Figure of a Subject must appear in the midst of the Picture, under the principal light, to distinguish it from the rest . A Painter who should think himself obliged strictly to follow this rule, would incumber himself with needless difficulties; he would be confined to great uniformity of composition, and be deprived of many beauties which are incompatible with its observance. In contrast, post-1900 examples are almost all of the type we saw in the current newspaper articles. This passage from W.H. Auden's (parodic) 1931 Address for a Prize-Day is a bit long, but it shows the pattern, and I enjoyed reading it: All of you must have found out what a great help it is, before starting on a job of work, to have some sort of scheme or plan in your mind beforehand. Some of the senior boys, I expect, will have heard of the great Italian poet Dante, who wrote that very difficult but wonderful poem, The Divine Comedy . In the second book of this poem, which describes Dante's visit to Purgatory, the sinners are divided into three main groups, those who have been guilty in their life of excessive love towards themselves or their neighbours, those guilty of defective love towards God and those guilty of perverted love. Now this afternoon I want, if I may, to take these three divisions of his and apply them to ourselves. In this way, I hope, you will be able to understand better what I am driving at. To start with, then, the excessive lovers of self. What are they like? These are they who even in childhood played in their corner, shrank when addressed. Lovers of long walks, they sometimes become bird watchers, crouching for hours among sunlit bushes like a fox, but prefer as a rule the big cities, living voluntarily in a top room, the curiosity of their landlady. Habituees of the mirror, famous readers, they fall in love with historical characters, with the unfortunate queen, or the engaging young assistant of a great detective, even with the voice, of the announcer, maybe, from some foreign broadcasting station they can never identify; unable to taste pleasure unless through the rare coincidence of naturally diverse events, or the performance of a long and intricate ritual. With odd dark eyes like windows, a lair for engines, they pass suffering more and more from cataract or deafness, leaving behind them diaries full of incomprehensible jottings, complaints less heard than the creaking of a wind pump on a moor. The easiest perhaps for you to recognise. They avoid the study fire, at games they are no earthly use. They are not popular. But isn't it up to you to help? Oughtn't you to warn them then against tampering like that with time, against those strange moments they look forward to so? Next time you see one sneaking from the field to develop photographs, won't you ask if you can come too? Why not go out together next Sunday; say, casually, in a wood: 'I suppose you realise you are fingering the levers that control eternity?' In that spirit, I'm going to get back to my chores, and recommend to Rob that he cut back on his 18th-century reading, and catch up with as a rule's last couple of centuries. Damn speech synthesizerIt is truly almost beyond belief that the Investor's Business Daily could say in an editorial (which after much ribald mockery on the blogs they have now altered): People such as scientist Stephen Hawking wouldn't have a chance in the U.K., where the National Health Service would say the life of this brilliant man, because of his physical handicaps, is essentially worthless. The minor issue for me is the fact that the NHS does not have what the Republicans allege are "death panels" that judge whether an individual's life is worth living. (There is a panel that decides if a drug is too expensive relative to the increase in length and quality of life it provides for — there's a limit to the quantities of public money the NHS will spend on supplying expensive drugs for free when they don't do much good. But that's not about judging individuals' lives.) No, the real kicker is that the journalists at IBD didn't even know that Stephen Hawking (long-time holder of the chair that Isaac Newton once held at the University of Cambridge) is a British physicist, and has lived his whole life in Britain! His motor neurone disease has been constantly and expertly treated under the NHS and he has received constant nursing care (he says, "I wouldn't be here today if it were not for the NHS. I have received a large amount of high-quality treatment without which I would not have survived"). It's a linguistic issue, of course: it's that damn speech synthesizer Hawking uses. The people at IBD have heard it speak his words, but they couldn't tell from its odd and mildly Swedish-flavored enunciation that he is not an American (and that would be the default assumption for anyone brilliant, naturally). Britain's speech scientists need to work on that synthesizer and get it talking more like Prince Charles. It looks like Americans' hopes of a reform of their broken health insurance system are going to depend on such things. If it is left up to IBD, and the sort of people who think Medicare is going to be taken over by the gov'ment, all hopes of reform are doomed. Stupid canine lexical acquisition claimsDogs as intelligent as two-year-old children, says a headline in the Daily Telegraph, a newspaper that is marketed to people of a conservative disposition and their dogs. And in case you did not quite understand the headline, they say it again in the subhead: "Dogs are as intelligent as the average two-year-old child, according to research by animal psychologists." It is bylined "By Richard Gray, Science Correspondent". (Science Correspondent! He almost certainly has a Master's degree, possibly in Science!) Research conducted at Language Log Plaza has shown a somewhat different result. Dogs are not as bright linguistically as a human two-year-old. But what is true is that dogs have the same general intelligence and ability to detect bullshit as the average Science Correspondent for the Daily Telegraph or BBC News. "The average dog is about as bright linguistically as a human two-year-old," said Professor Stanley Coren, a leading expert on canine intelligence at the University of British Columbia in Vancouver who has carried out the work. "This means they can understand about 165 words, signs and signals. Those in the top 20 per cent were able to understand as many as 250 words and signals, which is about the same as a two and a half year old. "Obviously we are not going to be able to sit down and have a conversation with a dog, but like a two-year-old, they show that they can understand words and gestures." The evidence of understanding words comes from experiments in which a border collie was trained to go and fetch a ball when "Ball!" was shouted at it, and so on for other medium-sized fetchables. (Ah, border collies. Long-time Language Log readers will recall that we have been here before.) And the evidence of mathematical calculations was that a trained border collie can work out the square root of an arbitrary integer written on a chalkboard, to an accuracy of at least three decimal places. No it wasn't. I said that just to see if you were paying attention. If you're a Daily Telegraph reader you probably believed me. The evidence was from differential gaze experiments: if you drop three doggie treats behind a screen and then surreptitiously remove one or two before shifting the screen, a dog looks a little bit longer at the remaining treat or treats than it does when all three are still there like they should have been. They are capable of noticing, in other words, when slightly weird shit is going down. If this all satisfies you — if you now think border collies can understand the meaning of lexical items and do mental arithmetic — then Professor Coren has won his game of spoof the public. But it has left me wondering whether I will be reading stories about lexical item acquisition in dogs and other stupid fake pet communication tricks until my dying day, or whether one day we will wake up on a bright new morning and Science Correspondents will have realized that they don't have to just paraphrase the press release put out at the APA convention, they can ask a few penetrating questions about what it means to understand the meaning of a word. (Like, could a dog understand an adverb, such as "surreptitiously"? Why is it always nouns and verbs triggering trained physical actions like fetching? I understand the noun "turd", but if you say it to me I don't run to try and find one.) [Hat tip: Brian Davies.] (I have left comments open below, but if you are a dog, please say so. On the Internet, nobody knows these things.) TransletterationA friend in Taiwan sent me the following inquiry: === "Early Thursday, the attackers sent out a wave of spam under the name Cyxymu, which is a Latin transliteration of the Cyrillic name of the capital of Abkhazia, Sukhumi." By which is meant that Latin Cyxymu is a "transliteration" of Cyrillic Сухуми (in italics С у х у м u ) . I think that this is an improper use of the word "transliteration" (to refer to "Sukhumi" as a transliteration of Cyxymu, however, would be correct), but I don't know what to call this rendering of Cyrillic Cyxymu as Latin "Cyxymu".
Arnold Zwicky: maybe it can be called "cross-alphabet transfer" David Beaver: transletteration Benjamin Zimmer: "Volapuk encoding," via The Tensor And Mark Swofford weighed in with this: There are probably discussions out there already on how the Russian word for restaurant appears (when written in all caps: "PECTOPAH" — sorry, not typed in real Cyrillic) to those who know the Latin but not Cyrillic alphabet as if it were a word pronounced "pectopah". Of course, that's just coincidence, not any sort of intentional letter play (at least on the part of the Russians). === 1. A Chinese friend of mine saw a sign near our home that depicted the tracks of a railroad followed by this word XING ("crossing"), which he read as 行 ("go")! 2. When I first went to Beijing in 1981, some naughty female clerks in a curio shop at the Temple of Heaven tried to embarrass me by showing me the word FUXING written on a piece of paper and asking me what it meant in English. I played dumb and insisted that it was a Chinese word (復興) meaning "rebirth, renaissance, resurgence," etc. My examples are not the same as the Cyxymu or Volapuk phenomenon, but all of these things seem like faux amis to me. Fry's English Delight: So Wrong It's RightStephen Fry — British comedian, quiz show host, and public intellectual — has just started a new series of his BBC Radio 4 program on the English language, "Fry's English Delight." In "So Wrong It's Right," Fry "examines how 'wrong' English can become right English." Our old friend the eggcorn makes an appearance about 11 minutes in. Jeremy Butterfield, author of A Damp Squid: The English Language Laid Bare, explains eggcorns to Fry (damp squid is an eggcornization of damp squib, in case you didn't know). Butterfield also talks about spelling changes, like the back-formation of pea(s) from pease, and how lexicographers use corpora to track changes in language (with specific reference to the Oxford English Corpus, the main subject of A Damp Squid). You can hear the whole thing online, at least for the next week.
And for more of Fry's linguistic musings, see my post, "Fry on the pleasure of language." (Hat tip, Damien Hall.) Speech science in social psychologyIn response to yesterday's post on "Linguistic analysis in social science", my old Bell Labs colleague Bob Krauss wrote that There may be more language-related research being done in social psychology than you're aware of. Attached is a chapter Jen Pardo and I contributed to a book about connections between social psych and other disciplines. I was glad to see the chapter, which was published a few years ago as Robert M. Krauss and Jennifer S. Pardo, "Speaker Perception and Social Behavior: Bridging Social Psychology and Speech Science", pp. 273-278 in Paul A.M. Van Lange (Ed.), Bridging Social Psychology: Benefits of Transdisciplinary Approaches, 2006. But reading this chapter, and skimming the rest of the book, confirmed my view that at present, there is remarkably little language-based research in the social sciences. Their (persuasive) abstract: Language plays a critical role in social life, and the semantic-pragmatic levels of linguistic analysis has become an important research focus in social psychology. Considerably less attention has been paid to the organized sound system that underlies speech. We distinguish between speech perception, which studies the processes underlying comprehension of the linguistic content of speech, and speaker perception, which examines effects of variability in speech that is not linguistically significant. Much of the latter deals with phenomena that lie at the heart of social psychology. We describe two broad research areas that illustrate the insights consideration of the phonological level of speech can contribute to an understanding of social behavior. Their (inspiring) conclusion: In this brief essay, we have argued that the sound structure of speech contains information that can contribute importantly to our understanding of social behavior. Speaker perception studies the way a particular utterance reflects a speaker's identity and internal state, and his/her definition of the situation. The variability that these factors produce can be studied both as a dependent variable and an independent variable. That is to say, we can examine the effects on voice of inductions involving activated identities, internal state or situational definitions; we also can examine how variability in features of voice (either natural or synthetically created) affect listeners' perceptions of the speaker and the semantic content of the utterance. I hadn't seen their chapter before, but I know most of the works in their bibliography. And in keeping with the theme of my earlier post, I'll predict that as digital audio archives become more and more available, and computational analysis and synthesis of "voice features" becomes more and more accessible, this kind of work should logically increase in prominence. After all, when Bob and I overlapped at Bell Labs 30-odd years ago, if you wanted (for example) to compare the "activated identities" of politicians as revealed in their speeches or press conferences, you'd need to buy audio tapes from media companies, have them physically shipped to you, and then digitize and analyze them using million-dollar minicomputers. ("In the snow, uphill, both ways.") Today you can download the audio for free over the internet,do acoustic analysis and synthesis on your laptop, and run perception experiments over the net as well. But despite Bob's 30-odd years of evangelism from positions of well-deserved authority and respect, and despite the fact that various forms of speech-and-language-based research are becoming easier and easier, it's still not very common for social psychologists to do the sort of research that he persuasively recommends. The Krauss and Pardo chapter is 5 pages in a 489-page book focusing broadly on interdisciplinary applications of social psychology — and I was unable to find any other discussion in the book of research based on linguistic analysis of any sort. ("Conversation analysis" and "discourse analysis" are mentioned once each, in a parenthetical and essentially contentless sort of way.) This sampled proportion (5/489 = 1%) strikes me as a plausible estimate for the field as a whole. Again, I predict that this is certain to change, as social-science researchers (and social psychologists in particular) respond to their changing environment. But the cultural conservatism of the academy means that it's going to take a while. |
|||||||||||||||||||||||||||||||||||||||||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}